
مدل یادگیری ماشین (ML Models) چیست؟ انواع، کاربردها

یادگیری ماشین (Machine Learning) یکی از مهمترین شاخههای هوش مصنوعی است که به سیستمها امکان میدهد بدون برنامهنویسی مستقیم، از دادهها یاد بگیرند. در این مقاله با مدلهای مختلف یادگیری ماشین، دستهبندی آنها، مدلهای پایه و کاربردهای واقعیشان آشنا میشویم.
مدلهای یادگیری ماشین معمولاً بر اساس نوع مسئله به سه دسته اصلی تقسیم میشوند: رگرسیون برای پیشبینی مقادیر عددی، دستهبندی برای تعیین برچسب یا کلاس، و خوشهبندی برای کشف الگوهای پنهان در دادههای بدون برچسب. درک تفاوت این مدلها، اولین گام برای طراحی یک سیستم هوشمند کارآمد است. انتخاب نادرست مدل میتواند منجر به کاهش دقت، افزایش خطا و حتی تصمیمگیریهای اشتباه در کاربردهای واقعی شود.
دسته بندی مدل های یادگیری ماشین
به طور کلی، مدلهای ML در سه دسته اصلی قرار میگیرند:
- Regression (رگرسیون)
- Classification (دستهبندی)
- Clustering (خوشهبندی)
1. Regression (رگرسیون)
رگرسیون یکی از مهمترین روشهای یادگیری ماشین است که برای پیشبینی مقادیر عددی پیوسته استفاده میشود. در این نوع مدلها، هدف تخمین یک مقدار واقعی بر اساس مجموعهای از ویژگیهای ورودی است. برای مثال، پیشبینی قیمت خانه بر اساس متراژ، موقعیت جغرافیایی و سال ساخت یک مسئله رگرسیون محسوب میشود. مدلهایی مانند Linear Regression و Polynomial Regression از رایجترین الگوریتمهای این حوزه هستند. معیارهایی مانند MSE و RMSE برای ارزیابی عملکرد مدلهای رگرسیون استفاده میشوند. رگرسیون زمانی کاربرد دارد که سؤال ما «چقدر؟» باشد و خروجی مورد انتظار یک عدد دقیق باشد.
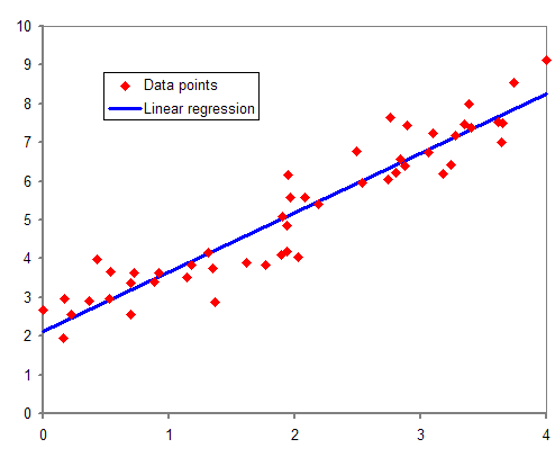
مثالها:
- پیشبینی قیمت مسکن
- پیشبینی میزان فروش
- تخمین مصرف انرژی
رگرسیون زمانی استفاده میشود که سوال ما «چقدر؟» باشد.
2. Classification (دسته بندی)
طبقهبندی روشی در یادگیری ماشین است که برای پیشبینی برچسب یا کلاس دادهها استفاده میشود. در این مدلها، خروجی به صورت گسسته تعریف میشود؛ برای مثال تشخیص ایمیل Spam یا Not Spam، یا پیشبینی مثبت یا منفی بودن یک آزمایش پزشکی. الگوریتمهایی مانند Logistic Regression، Decision Trees و K-Nearest Neighbors از مدلهای پرکاربرد در این حوزه هستند. برای ارزیابی این مدلها معمولاً از معیارهایی مانند Accuracy، Precision، Recall و F1-Score استفاده میشود. طبقهبندی زمانی مناسب است که مسئله شامل انتخاب بین چند دسته مشخص باشد و سؤال اصلی «کدام دسته؟» باشد.
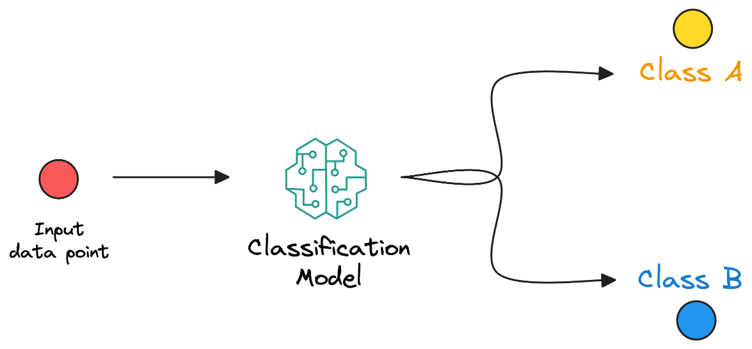
مثالها:
- تشخیص ایمیل Spam یا Not Spam
- تشخیص بیماری مثبت یا منفی
- شناسایی نوع تصویر
این مدلها زمانی کاربرد دارند که سوال ما «به کدام دسته تعلق دارد؟» باشد.
3. Clustering (خوشه بندی)
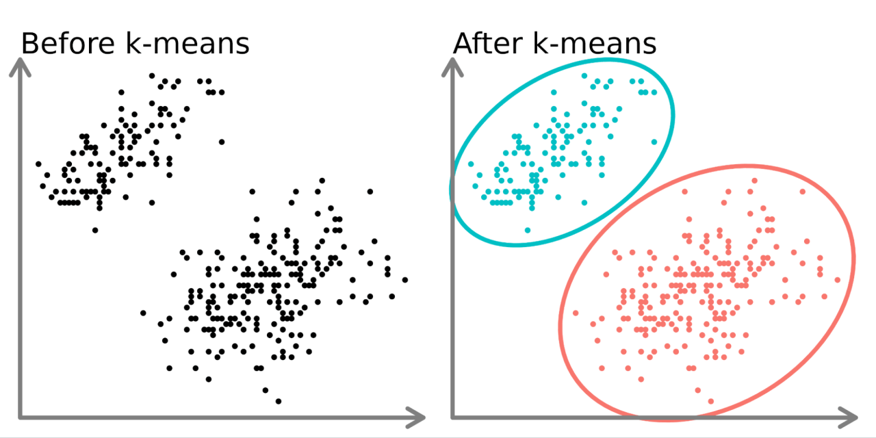
مثالها:
- گروهبندی مشتریان بر اساس رفتار خرید
- تحلیل بازار
- تقسیم کاربران یک اپلیکیشن به گروههای رفتاری
این مدلها برای کشف الگوهای پنهان در دادهها استفاده میشوند.

مدل های پایه یادگیری ماشین
در ادامه با مهمترین مدلهای پایهای که هر دانشجوی ML باید بشناسد آشنا میشویم.
مدل های رگرسیون
مدلهای رگرسیون برای پیشبینی مقادیر عددی پیوسته استفاده میشوند. خروجی این مدلها یک عدد واقعی است.
Linear Regression
Linear Regression یکی از سادهترین و پرکاربردترین مدلهای رگرسیون در یادگیری ماشین است. این مدل رابطهای خطی بین متغیرهای مستقل و متغیر وابسته برقرار میکند و تلاش میکند بهترین خط برازش را روی دادهها پیدا کند. هدف آن کمینهسازی خطا بین مقدار واقعی و مقدار پیشبینیشده است که معمولاً با روش Least Squares انجام میشود. این مدل در پیشبینی قیمت خانه، تحلیل روند فروش و تخمین شاخصهای اقتصادی کاربرد دارد. سادگی، سرعت بالا و قابلیت تفسیر آسان از مهمترین مزایای Linear Regression هستند، اما در روابط غیرخطی عملکرد ضعیفتری دارد.
Polynomial Regression
Polynomial Regression نسخه توسعهیافتهای از رگرسیون خطی است که برای مدلسازی روابط غیرخطی استفاده میشود. در این روش، ویژگیها به توانهای بالاتر تبدیل میشوند تا منحنی مناسبتری روی دادهها برازش شود. این مدل زمانی کاربرد دارد که رابطه بین متغیرها خطی نباشد اما بتوان آن را با یک تابع چندجملهای تقریب زد. در مسائل پیشبینی رشد جمعیت، تحلیل دادههای علمی و مدلسازی روندهای پیچیده کاربرد دارد. با این حال، اگر درجه چندجملهای بیش از حد بالا باشد، ممکن است مدل دچار Overfitting شود و روی دادههای جدید عملکرد ضعیفی داشته باشد.
Ridge Regression
Ridge Regression نوعی رگرسیون منظمسازیشده (Regularized) است که برای کاهش مشکل Overfitting استفاده میشود. این مدل با اضافه کردن یک جمله جریمه (Penalty Term) به تابع هزینه، ضرایب بزرگ را محدود میکند. در دادههایی که همبستگی بالایی بین ویژگیها وجود دارد، Ridge Regression عملکرد پایدارتری نسبت به Linear Regression ارائه میدهد. این روش در تحلیل دادههای با ابعاد بالا، مانند دادههای مالی و ژنتیکی، بسیار کاربردی است. مزیت اصلی آن کاهش واریانس مدل و بهبود تعمیمپذیری است، هرچند ممکن است کمی از دقت روی دادههای آموزشی بکاهد.
مدل های دسته بندی
مدلهای دستهبندی برای پیشبینی یک برچسب یا کلاس مشخص استفاده میشوند.
Logistic Regression
Logistic Regression مدلی آماری برای مسائل دستهبندی دودویی است. برخلاف نام آن، این مدل برای پیشبینی مقادیر عددی استفاده نمیشود، بلکه احتمال تعلق یک نمونه به یک کلاس خاص را محاسبه میکند. خروجی آن عددی بین 0 و 1 است که با استفاده از تابع سیگموید تولید میشود. این مدل در تشخیص بیماری، پیشبینی تقلب مالی و تحلیل رفتار کاربران کاربرد دارد. سادگی، سرعت بالا و قابلیت تفسیر ضرایب از مزایای آن است، اما در مسائل بسیار پیچیده یا غیرخطی ممکن است دقت کافی نداشته باشد.
Decision Tree
Decision Tree مدلی ساختاریافته و قابل تفسیر است که فرآیند تصمیمگیری را به صورت درختی نمایش میدهد. هر گره نشاندهنده یک شرط روی ویژگیهاست و هر شاخه یک تصمیم را نمایش میدهد. این مدل میتواند هم برای دستهبندی و هم برای رگرسیون استفاده شود. مزیت اصلی آن شفافیت و قابلیت توضیح نتایج است. در سیستمهای تشخیص پزشکی، اعتبارسنجی و تحلیل ریسک کاربرد دارد. با این حال، درختهای عمیق ممکن است دچار Overfitting شوند، بنابراین معمولاً از تکنیکهایی مانند Pruning برای کنترل پیچیدگی استفاده میشود.
K-Nearest Neighbors (KNN)
KNN یک الگوریتم ساده و مبتنی بر فاصله است که بر اساس نزدیکترین همسایهها تصمیمگیری میکند. در این روش، برای پیشبینی کلاس یک داده جدید، K نمونه نزدیکتر در فضای ویژگیها بررسی میشوند و کلاس غالب به عنوان خروجی انتخاب میشود. این مدل نیاز به مرحله آموزش پیچیده ندارد و بیشتر در زمان پیشبینی محاسبات انجام میدهد. در تشخیص الگو، سیستمهای پیشنهاددهنده و مسائل دستهبندی کوچک کاربرد دارد. انتخاب مقدار مناسب K و معیار فاصله تأثیر زیادی بر عملکرد مدل دارد.
مدل های خوشه بندی
مدلهای خوشهبندی دادههای بدون برچسب را بر اساس شباهت گروهبندی میکنند.
K-Means
K-Means یکی از محبوبترین الگوریتمهای خوشهبندی است که دادهها را به K گروه تقسیم میکند. این الگوریتم با انتخاب مراکز اولیه (Centroids) شروع میشود و به صورت تکراری دادهها را به نزدیکترین مرکز اختصاص میدهد. سپس مراکز بهروزرسانی میشوند تا زمانی که همگرایی حاصل شود. این روش در تقسیمبندی مشتریان، تحلیل بازار و پردازش تصویر کاربرد دارد. سرعت بالا و سادگی از مزایای آن است، اما نیاز به تعیین تعداد خوشهها از قبل یکی از محدودیتهای آن محسوب میشود.
Hierarchical Clustering
Hierarchical Clustering روشی سلسلهمراتبی برای ایجاد خوشههاست که به صورت درختی (Dendrogram) نمایش داده میشود. این الگوریتم میتواند به صورت تجمعی (Agglomerative) یا تقسیمی (Divisive) اجرا شود. در روش تجمعی، هر داده ابتدا یک خوشه جداگانه است و به تدریج خوشهها با هم ادغام میشوند. این مدل برای تحلیل ساختار داده و کشف روابط پنهان بسیار مفید است. مزیت آن عدم نیاز به تعیین تعداد خوشهها در ابتداست، اما از نظر محاسباتی برای دادههای بزرگ سنگینتر از K-Means است.
DBSCAN
DBSCAN یک الگوریتم خوشهبندی مبتنی بر چگالی است که دادهها را بر اساس تراکم نقاط در فضا گروهبندی میکند. این مدل میتواند خوشههایی با شکلهای غیرمنظم را شناسایی کند و همچنین نقاط پرت (Outliers) را تشخیص دهد. برخلاف K-Means، نیازی به تعیین تعداد خوشهها از قبل ندارد. DBSCAN در تحلیل دادههای مکانی، تشخیص ناهنجاری و دادههای جغرافیایی بسیار کاربرد دارد. انتخاب پارامترهای مناسب مانند epsilon و حداقل تعداد نقاط، نقش مهمی در عملکرد صحیح این الگوریتم دارد.
کاربرد مدل های یادگیری ماشین در دنیای واقعی
امروزه مدلهای یادگیری ماشین در حوزههایی مانند تحلیل بازار، پزشکی، امور مالی، پردازش تصویر و سیستمهای پیشنهاددهنده نقش کلیدی دارند. بنابراین آشنایی با انواع مدلها و کاربردهای آنها، برای هر فردی که قصد ورود به حوزه علم داده و هوش مصنوعی را دارد، یک ضرورت محسوب میشود. یادگیری ماشین فقط یک مفهوم تئوری نیست، بلکه در صنایع مختلف کاربرد گسترده دارد.
کاربرد Regression
- پیشبینی قیمت املاک
- پیشبینی فروش آینده
- تحلیل روندهای مالی
کاربرد Classification
- تشخیص ایمیل اسپم
- تشخیص تقلب بانکی
- سیستمهای تشخیص بیماری
کاربرد Clustering
- تقسیمبندی مشتریان
- تحلیل بازار و رفتار مصرفکننده
- شخصیسازی تبلیغات
جمعبندی
مدلهای یادگیری ماشین به سه دسته اصلی رگرسیون، دستهبندی و خوشهبندی تقسیم میشوند. هر کدام کاربرد خاص خود را دارند و انتخاب مدل مناسب به نوع داده و هدف مسئله بستگی دارد. همچنین ابزارهایی مانند آناکوندا نقش مهمی در پیادهسازی و مدیریت پروژههای یادگیری ماشین دارند.
اگر قصد ورود حرفهای به حوزه هوش مصنوعی و علم داده را دارید، شناخت این مدلها و ابزارها اولین قدم ضروری است.
